A Powerful Tool for Data Analytics: Introduction to ClickHouse
TL;DR ClickHouse is the OLAP performance beast with columnar storage and vectorized execution
ClickHouse is an open-source database for real-time data analytics developed by Yandex, initially used in multiple data analytics projects internally at Yandex. To introduce ClickHouse, we first need to introduce Yandex. ClickHouse’s emergence is closely related to Yandex’s business needs. Yandex is Russia’s largest search engine, with many data analytics projects. The largest of these by data volume is Yandex.Metrica, a website analytics service similar to Baidu Analytics, with data volume second only to Google Analytics. Since ClickHouse was open-sourced, many companies both domestically and internationally have begun using it in their production systems. Therefore, I’m writing this ClickHouse tutorial to provide a basic introduction.
Overview
ClickHouse is extremely well-suited for OLAP (Online Analytical Processing) problems. These types of problems have the following characteristics:
- Requests are predominantly reads; data additions and updates are generally performed in batches;
- Tables can be very wide, but actual queries typically only involve a limited number of columns;
- Column values are generally small, typically numbers or short strings;
- The query result set is significantly smaller than the source data;
- Transaction processing requirements are relatively weak
According to the performance benchmarks provided by ClickHouse, its performance far exceeds all competing products.
The core approach used for this type of problem is columnar storage. Commonly used databases like MySQL use row-based storage. Columnar storage, simply put, stores data from the same column together, as shown in the following diagram.
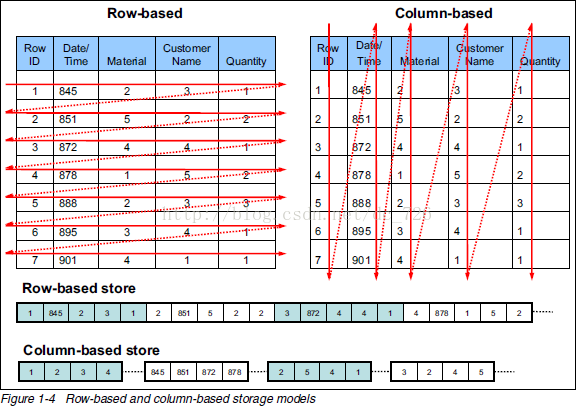
Compared to row-based storage, columnar storage only reads the relevant columns during queries, reducing I/O overhead; any column can serve as an index; however, data writes are relatively more complex. Comparing with the OLAP problem characteristics we described earlier, we can see that columnar storage is extremely well-suited for online data analytics.
ClickHouse Storage Engines
ClickHouse provides many storage engines, but the MergeTree engine is sufficient for over 90% of use cases. Let’s look at this engine in detail.
Simply put, MergeTree has the following characteristics:
- Data is stored in parts (typically partitioned by date);
- Within each part, data is sorted by primary key and divided into multiple blocks;
- New parts are generated on each insert;
- Asynchronous merging
First, let’s look at the file structure of MergeTree. (The images in this section are from the ClickHouse Chinese community (http://clickhouse.com.cn/), shared by Teacher Gao Peng from Sina)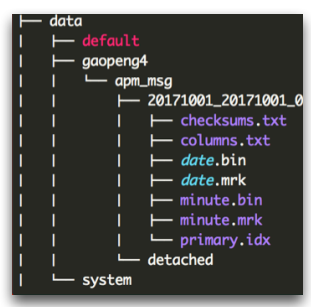
The directory like 20171001…. represents a part. The files within include: columns.txt records column information; each column has a bin file and an mrk file, where the bin file contains the actual data. primary.idx stores primary key information, with a structure similar to mrk, like a sparse index.
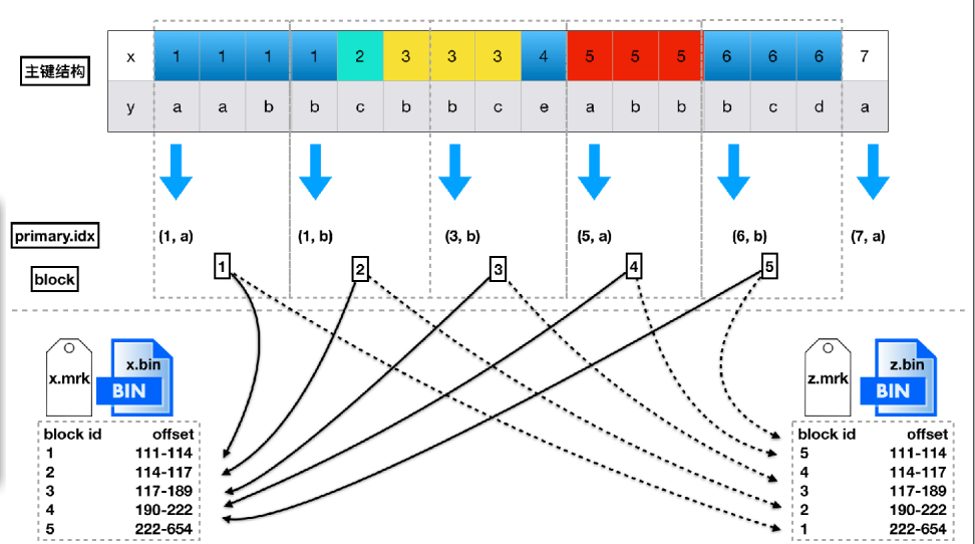
This shows the specific structure of mrk and primary files. As we can see, data is sorted by primary key and divided into blocks at regular intervals. Each block also extracts one data point as an index, stored in primary.idx and each column’s mrk file.
When querying with MergeTree, the most critical step is locating the block. This differs depending on whether the queried column is part of the primary key. Queries on the primary key have better performance, but non-primary-key queries also perform reasonably well due to columnar storage—even though a full scan is performed. So indexes are not as critical in ClickHouse as they are in MySQL. In practice, you generally need to add date-based query conditions to ensure performance for non-primary-key queries.
After finding the corresponding block, the next step is to search for data within the block, retrieve the needed rows, and assemble the other column data.
Other Features
Data Compression
Some column-oriented DBMSs (such as InfiniDB CE and MonetDB) do not use data compression. However, data compression plays a significant role in ClickHouse’s performance. For columnar storage, fields of the same type stored together with similar data are much easier to compress. ClickHouse supports compression algorithms such as LZ4 and ZSTD.
Disk-Based Storage
ClickHouse supports standard disks, giving it a significant cost advantage.
It provides configurations for RAID, SSD, and large memory, which can be leveraged if available.
Data is stored in primary key order, enabling queries with extremely low latency.
Vectorized Engine
Modern CPUs feature a mechanism called SIMD (Single Instruction, Multiple Data), where a single instruction operates on multiple data points. For columnar storage data, this mechanism can be easily leveraged to better utilize CPU performance.
Multi-Core and Multi-Server Parallel Processing
In ClickHouse, data is stored across different shards. Queries are executed in parallel across multiple shards.
On each server, multi-core parallel processing is also used to fully utilize single-machine performance.
Real-Time Data Ingestion
With the MergeTree engine, newly inserted data first forms a new part, at which point the data is already queryable. Therefore, the latency from data write to queryability is very small. Subsequently, different parts continue to be merged asynchronously to improve storage efficiency.
Data Replication
ClickHouse uses ZooKeeper-based master-master replication. After writing to any available replica, data is distributed to all remaining replicas. Replication is performed block by block, and failed replications can be directly retried. The system maintains identical data across different replicas.
Additionally, compared to other columnar databases, ClickHouse has excellent support for SQL syntax, including common SQL statements like GROUP BY, ORDER BY, IN, and JOIN.
Quick Start Guide
- Install ClickHouse: On Ubuntu:
sudo apt-get install clickhouse-server clickhouse-client. Start the service and connect withclickhouse-client. - Create table: Use the MergeTree engine, specify
ORDER BY(sort key) andPARTITION BY(partition key, typically by date). Define columns as needed — no per-column indexes required like in MySQL. - Import data: Use
clickhouse-client --query "INSERT INTO table FORMAT CSV" < data.csvor theclickhouse-localtool for bulk import. Data is queryable immediately; merges happen in the background. - Write queries: Use standard SQL for analysis. ClickHouse has solid support for
GROUP BY,ORDER BY,JOIN, etc. Add date filters to boost non-primary-key query performance. - Compare MySQL performance: Load the same data into MySQL and ClickHouse, run identical aggregation queries, and experience the order-of-magnitude difference that columnar storage makes for OLAP workloads.
 微信
微信