[Translation] [On Distributed Architecture and System Design] Patterns of Distributed Systems - Overview
TL;DR Martin Fowler summarizes common distributed system patterns — such as write-ahead logging, quorum, and leader-follower replication — addressing core challenges like process crashes and network partitions.
(I recently reorganized this article. Welcome to read the latest version: https://lichuanyang.top/posts/45718/)
This article is translated from https://martinfowler.com/articles/patterns-of-distributed-systems/. The original author summarizes various distributed systems used in enterprise architectures, extracting common “patterns.” As the first article in this series, it introduces the characteristics of distributed systems and some common issues. I highly recommend reading this article and the original English version — they will be very helpful for understanding distributed system design and distributed architecture philosophy.
What This Is About
Distributed systems bring special challenges to program design. They typically require us to have multiple data replicas that need to stay in sync. However, we cannot expect all nodes to work reliably all the time, and network delays can easily lead to inconsistencies. Despite this, many organizations rely on a range of core distributed systems for data storage, messaging, system management, and computation. These systems face many common problems, which can also be solved with similar approaches. This article defines these solutions as patterns, through which we can build a better understanding of how to understand, communicate about, and teach distributed systems.
Over the past few months, I have been conducting workshops on distributed systems at ThoughtWorks. One of the main challenges is how to map the theory of distributed systems to open-source projects like Kafka and Cassandra, while keeping the discussion general enough to cover a broader range of solutions. The concept of patterns provides a nice way out.
The “pattern” structure essentially allows us to focus on a specific problem and clearly articulate why a particular solution is needed. The description of the solution then allows us to present a code structure that is concrete enough to represent an actual solution, yet general enough to cover various variations. Patterns also allow us to chain various patterns together to build a complete system. In this way, we have a sufficient vocabulary to discuss distributed system implementations.
What follows is the first set of patterns observed in mainstream open-source distributed systems. I hope this set of patterns is useful for all developers.
Distributed Systems — Implementation Perspective
Current enterprise architectures contain many naturally distributed platforms and frameworks. If we sample the platforms and frameworks in a typical architecture today, we see the following:
| Type of platform/framework | Example |
|---|---|
| Databases | Cassandra, HBase, Riak |
| Message Brokers | Kafka, Pulsar |
| Infrastructure | Kubernetes, Mesos, Zookeeper, etcd, Consul |
| In Memory Data/Compute Grids | Hazlecast, Pivotal Gemfire |
| Stateful Microservices | Akka Actors, Axon |
| File Systems | HDFS, Ceph |
These systems are all naturally distributed. Regarding what makes a system “distributed,” there are two aspects:
- Running on multiple servers. The number of servers in a cluster can vary greatly, from three to thousands.
- Needing to handle data, which makes them inherently “stateful” systems.
When multiple servers are involved in storing data, there are several ways things can go wrong. All the systems listed above need to solve these problems. There are recurring solution patterns in how these systems are implemented. Understanding these solutions in a more general form helps in understanding the wide range of implementations and serves as good guidance when building new systems.
Patterns, proposed by Christopher Alexander, are widely accepted in the software community as a way to document design architecture in software system design. Patterns provide a structured way to solve problems through repeated observation and verification. An interesting way to use patterns is to chain multiple patterns together in the form of a pattern sequence or pattern language, which provides some guidance for implementing “the whole” or a complete system. Viewing distributed systems as a series of patterns is an effective way to gain deeper insight into their implementations.
Problems and Their Recurring Solutions
When data is stored across multiple servers, there are several ways things can go wrong.
Process Crashes
A process can crash at any time due to hardware or software factors. There are several ways a process can crash:
- System administrators perform routine system maintenance, and the process is shut down.
- An I/O operation fails due to insufficient disk space, and the exception is not handled correctly, causing the process to be killed.
- In cloud environments, things can be more complex; various unrelated reasons can cause system downtime.
Most importantly, if a process is responsible for storing data, it must be designed to provide durability guarantees for data stored on the server. Even if the process crashes suddenly, it should retain all data for which it has already acknowledged receipt from the client. Depending on the access pattern, different storage engines have different storage structures, ranging from simple hash tables to complex graph structures. Flushing data to disk is one of the most time-consuming operations, so it’s not possible to flush every insert or update to disk immediately. Therefore, most databases have in-memory storage structures, with data periodically flushed to disk. If the process crashes suddenly, all of this data may be lost.
A technique called Write-Ahead Log is used to solve this problem. The server stores each state change as a command in an append-only file on disk. Append operations are typically very fast, so they can be completed without impacting performance. Sequential writes to a single log file store each update. On server startup, the log can be replayed to rebuild the in-memory state.
This provides durability guarantees. Even if the server crashes suddenly and restarts, data is not lost. However, clients will not be able to read or store any data until the server recovers. Therefore, if a server fails, we lack availability.
An obvious solution is to store data on multiple servers. Thus, we can replicate the write-ahead log across multiple servers.
When multiple servers are involved, there are more failure scenarios to consider.
Network Latency
In the TCP/IP protocol stack, there is no upper bound on the delay caused by transmitting messages over the network. It varies based on network load. For example, a 1 Gbps network connection can be overwhelmed by large batch jobs that run periodically, filling network buffers and potentially causing some messages to reach the server with indefinite delays.
In a typical data center, servers are packed into racks, and multiple racks are connected through rack switches. There may be a tree of switches connecting one part of the data center to another. In some cases, a group of servers can communicate with each other but is disconnected from another group of servers. This situation is called a network partition. One of the fundamental problems with servers communicating over the network is determining when a particular server has failed.
There are two problems to solve:
- A particular server cannot know indefinitely whether another server has gone down.
- There should not be two sets of servers, each believing the other has failed, and therefore continuing to serve different clients. This is called split brain.
To solve the first problem, each server periodically sends heartbeat messages to other servers. If no heartbeat is received, the corresponding server is considered crashed. Heartbeat intervals are short enough to ensure that server failure is detected quickly. In the worst case, a server may still be running but is considered down by the cluster as a whole, and continues to operate. This heartbeat mechanism ensures that the service provided to clients is not interrupted.
The second problem is split brain. In a split-brain situation, if two groups of servers independently accept updates, different clients can read and write different data. Once the split-brain issue is resolved, it is impossible to automatically reconcile the conflicts.
To solve the split-brain problem, we must ensure that two disconnected groups of servers cannot continue to operate independently. To ensure this, a server only considers an action successful if a majority of servers can acknowledge it. If the servers cannot elect a majority, they will be unable to serve, and some client groups may not receive the service. However, the servers in the cluster will always be in a consistent state. The number of servers forming a majority is called a Quorum. How is the Quorum determined? It is based on the number of failures the cluster can tolerate. For example, if we have a five-node cluster, we need a Quorum of three. Typically, if we want to tolerate f failures, we need a cluster size of 2f + 1.
A Quorum ensures we have enough data replicas to withstand some server failures. However, this alone is not enough to provide strong consistency guarantees to clients. Suppose a client initiates a write on the Quorum, but the write succeeds on only one server. Other servers in the Quorum still have old values. When the client reads from the Quorum, it may get the latest value if the server with the latest value is available. However, if the server with the latest value is unavailable when the client starts reading, it could get the old value. To avoid this, someone needs to track whether the Quorum agrees on a particular operation and only send values to clients that are guaranteed to be available on all servers. This is where the Master-Slave pattern is used. One server is elected as the master, and the other servers act as slaves. The master controls and coordinates replication to the slaves. The master needs to determine which changes should be visible to clients. A High-Water Mark is used to track entries in the write-ahead log that have been successfully replicated to enough slaves. Clients can see all entries before the high-water mark. The master also sends the high-water mark to slaves. Therefore, if the master fails and one of the slaves becomes the new master, clients will not see inconsistencies.
Process Pauses
But that’s not all. Even with Quorums and Master and Slave, there is still a tricky problem to solve. The master process can pause at any time. There are many reasons for process pauses. In languages that support garbage collection, there may be long garbage collection pauses. A master with long garbage collection pauses may disconnect from the slaves and resume sending messages after the pause ends. Meanwhile, if the slaves haven’t received any heartbeat from the master, they may have elected a new master and accepted client updates. If the old master’s requests are processed as-is, they may overwrite some updates. Therefore, we need a mechanism to detect requests from a stale master. A Generation Clock is used to tag and detect requests from an old master. A generation is a monotonically increasing number.
Clocks Not in Sync and Message Ordering
The problem of detecting old master messages from newer ones is how to guarantee message ordering. It may seem that we can use system time to order a set of messages, but in practice, we cannot. The main reason is that we cannot guarantee that system clocks across servers are synchronized. The clock on a computer during the day is managed by a quartz crystal and measures time based on the crystal’s oscillation.
This mechanism is error-prone because the crystal can oscillate faster or slower, so different servers may have significantly different times. The clocks on a set of servers are synchronized through a service called NTP. This service periodically checks a set of global time servers and adjusts the computer clock accordingly.
Since this happens through network communication, and network latency can vary as described in the previous sections, clock synchronization may be delayed due to network issues. This can cause server clocks to drift from each other and even go backward after NTP synchronization. Due to these issues with computer clocks, wall-clock time is generally not used for ordering events. Instead, a simple technique called Lamport’s timestamp is used. The Generation Clock is one example of this.
Putting It All Together — A Distributed System Example
We can see how understanding these patterns from the ground up helps us build a complete system. We’ll use Consensus as an example. Distributed consensus is a specific implementation of distributed systems that provides the strongest consistency guarantees. Popular examples in enterprise architectures include Zookeeper, etcd, and Consul. They implement consensus algorithms such as ZAB and Raft to provide replication and strong consistency. There are other popular algorithms that implement consensus: Paxos used in Google’s Chubby for the locking service, and consider stamp replication and virtual synchrony. In very simple terms, consensus means that among a set of servers, they agree on what data is stored, the order in which it is stored, and when that data becomes visible to clients.
Pattern List for Implementing Consensus
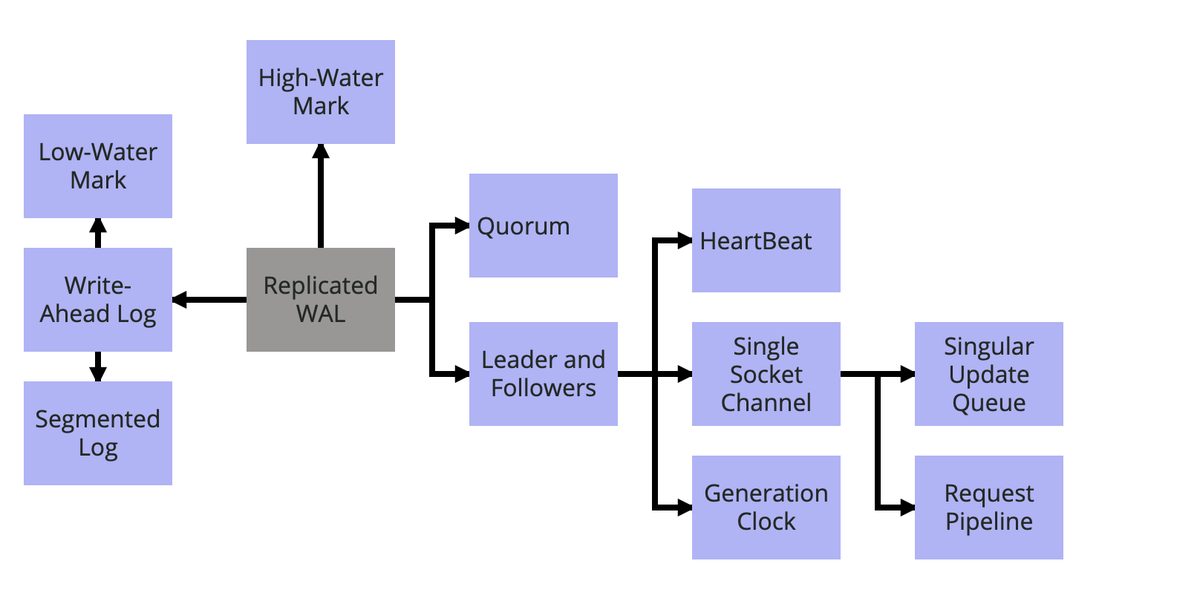
The implementation of consensus uses state machine replication for fault tolerance. In state machine replication, a storage service, such as a key-value store, is replicated across all servers, and user inputs are executed on each server in the same order. The key implementation technique used for this purpose is replicating the Write-Ahead Log across all servers to create a “Replicated WAL.”
We can combine these patterns to implement a Replicated WAL as follows:
To provide durability guarantees, the Write-Ahead Log is used. The Segmented Log divides the write-ahead log into multiple segments. This helps the Low-Water Mark with log cleanup. Fault tolerance is provided by replicating the write-ahead log across multiple servers. Replication between servers is managed using the Master-Slave pattern. The Quorum is used when updating the High-Water Mark to determine which values are visible to clients. The Single Update Queue ensures all requests are processed in strict order. The Single Socket Channel is used to send master requests to slaves, maintaining event ordering. To optimize throughput and latency on the Single Socket Channel, the Request Pipeline is used. The slave determines master availability through Heartbeats. If the master is temporarily disconnected from the cluster due to a network partition, the Generation Clock can be used to detect it.
By understanding these problems and their common solutions in this way, we can understand how to build complex systems.
Next Steps
Distributed systems are a vast topic. The set of patterns covered here is just a small portion, spanning different categories to show how the pattern approach helps in understanding and designing distributed systems. I will continue to add the following topics to this collection:
- Group Membership and Failure Detection
- Partitioning
- Replication and Consistency
- Storage
- Processing
Original article: https://lichuanyang.top/posts/3914/
 微信
微信