高并发下作余额扣减的一些经验
前一段时间参加了优化一个老的计费系统,学习了一些高并发下做余额扣减的常用手段,也做了一些尝试,因此在这里总结记录一下, 在高并发下对。 问题描述对于一个计费系统来说,并发问题事实上分为两类,一类是应用并发高,也就是纯粹的用户量大,访问量多,这类问题和一般的高并发问题没有区别,用分布式等手段就可以解决;另外一类问题则是一般分布式手段无法解决的用户高并发问题,也是本文要着重说的。这类问题源自对某些高频账号,大量的并发访问,会导致瓶颈首先出现在某些数据库记录上,大量操作由于无法竞争到数据库的行锁而导致等待,这些等待中的操作又会占用其他资源,最终导致系统不可用。针对这类问题,下边介绍一些常用的处理办法。 不设置余额字段由于对于一个稳定的计费来说,一定是会记录计费流水明细的,所以完全可以不设置余额字段,而采用根据流水明细计算的方式来获取余额。不过这种方法不是万能的,比如拿广告业务的计费系统来说,频率非常高,而每次的金额很小,这时候想通过计算求和去算余额,显然是不现实的。 合并与拆分这是两种方式,因为有一些相似之处,都是要降低对单条数据库记录的访问压力,所以也就放到一起说了。合并,就是对...
java细节:三目运算符和自动拆箱
问题引入今天用findbugs扫代码时遇到一个很有意思的问题,有关三目运算符的,在这儿记录一下。 就是类似这么一行代码: 12boolean b = true; Long a = b ? 0l : Long.valueOf(2); Findbugs给出了”Boxed value is unboxed and then immediately reboxed”的提示,意思就是有装箱的对象做了拆箱,然后又马上做了装箱。这个问题其实很常见,一开始也没注意,只是习惯性的把Long.valueOf 改成了Long.parseLong, 确实把这个警告消掉了,不过之后才意识到不对:明明valueOf返回的是Long类型,parseLong返回的是long类型,而需要的正是Long类型,为什么反而用valueOf的时候有问题呢。 其实思考一下大概也能想明白,主要就在三元运算符的另一个分支,因为另一个分支返回的是一个未装箱的0,所以这个三元运算符的返回值就成了long,所以原本的Long类型就要经过一次拆箱才会被返回。要优化这个部分的话,保持两个分支的返回类型一致就可以了。 然后把相...
设计一个开源的北京地铁路线规划小工具 java版本
概述最近在找房子,因为想找一个去几个地方都相对方便的位置,自己去地图上看还挺麻烦的,所以想做个小工具,用来对北京地铁的路线做规划,本文就简单介绍一下实现过程。目前的功能还比较简单,主体方法就是根据一个输入的始发站,列出其他所有站点到这个地方的站数最少路线。 数据获取从网上找了高德地图的接口数据: http://map.amap.com/service/subway?_1469083453978&srhdata=1100_drw_beijing.json . 对拿到的json串进行解析,其中包含每条地铁线路的信息,并依次列出线路上的每个站点。 通过解析数据,要得到的主要就是各个站点的信息,站点定义的数据结构如下: 123456private String id;private String name;private Set<String> lines = new HashSet<String>(); //所在线路private String position;private String pinyin;private Set<String&...
redis cluster的数据迁移
在之前的一篇文章通过实际操作理解redis cluster原理中,我们简单介绍过redis cluster的设计原理。redis cluster中的数据是根据一定规则分配到16384个slot中,这些slot又根据配置对应到不同的节点上。我们知道,在集群稳定运行后,仍然可以以slot为单位转移数据,不过对于具体的转移过程,包括转移过程中集群的可用性等问题,一直不是太确定,所以这次详细了解了一下。 整体流程redis官方文档中提供的数据迁移办法是借助redis-trib脚本,其实严格来说,这个redis-trib并不是redis本体的一部分,它只是官方按照redis设计规范实现的一套脚本集合,帮助用户更方便的使用redis-cluster。 实际上,我们完全可以脱离这个脚本来使用cluster, 或者用其他方式实现这套逻辑,比如搜狐tv的redis运维工具cachecloud里,就用java实现了整套逻辑。 我们可以参考redis-trip或者cachecloud的代码来了解cluster数据迁移的流程,主要分为如下几部: 设定迁移中的节点状态,比如要把slot x的数据从节...
jstorm源码解析之循环任务AsyncLoopThread
概述AsyncLoopThread是jstorm里自定义的一个循环执行任务的工具,实现不复杂,本来是不值当的专门开一篇文章介绍。不过这个在jstorm里应用实在太广泛了,诸如uspervisor/nimbus心跳,获取新topology,更新worker状态等大量功能都是利用AsyncLoopThread实现的,所以还是介绍一下吧,也方便后续看其他部分代码。 使用AsyncLoopThread其实完全可以拿出来用在我们自己的工程里,使用比较方便,可以参考 https://github.com/lcy362/Scenes/blob/4d8ec4ff166060cf5d491c33a96f5c86e8389333/src/main/java/com/mallow/jstormcode/AsyncLoop.java 只需要先定义一个RunnableCallback类,RunnableCallback是jstorm里封装的一个线程类,对Runable接口做了一些增强,可以回调,可以主动关闭。 123456789101112public class TestThread ex...

activemq特性之持久化
介绍数据的持久化是很多系统都会涉及到的一个问题,尤其是redis,activemq这些数据主要是存储在内存中的。既然存在内存中,就会面临宕机时数据丢失的风险。这一问题的解决方案就是通过某种方式将数据落到磁盘上,也就是所谓的持久化。 activemq提供了三种持久化方式,分别基于jdbc, kahadb和leveldb. 目前官方最推荐的是基于kahadb的持久化。 jdbc是activemq最早提供的一种持久化方式,但是用数据库去做持久化确实不合适,毕竟性能有瓶颈,而且只是需要简单的读写数据,不需要数据库各种强大的功能。现在去看文档的话,连基本的配置都被埋的很深,所以这种方式我们也就不细说了。 正是由于基于jdbc的方式存在的种种问题,activemq后来就接连提供了基于kahabd和leveldb的持久化方式.leveldb 是google开源的一个KV磁盘存储系统,应用很广,kahadb没找着源头,应该就是activemq团队开发的,也是一种基于磁盘的存储系统。按理说,leveldb的性能是要好一些的,之前无论是activemq的默认配置,还是文档里的推荐使用方法,都是首选l...
activemq的安装及基本使用
安装从官网下载最新版本,解压,其他的前期准备只需要安装jdk。 从activemq 5.14开始,只支持jdk8。 配置核心配置文件是conf目录下的activemq.xml, 默认的配置无需修改即可使用,其他配置我们会在后续文章介绍activemq各种特性时详细介绍。 启动bin目录下运行 activemq start 即可 ,启动之后浏览器打开localhost:8161 可以打开web管理页面。 基本api使用这里只介绍java下的api使用,activemq默认的openwire协议是只支持java的,因为实现的JMS协议是java下的协议。如果有其他语言的访问需求,可以用stomp,amqp等协议。 依赖包引入activemq官方的client包。 1234<dependency> <groupId>org.apache.activemq</groupId> <artifactId>activemq-client</artifactId></dependency> actibemq收发消息的主要步...
activemq系列-概述
ActiveMQ 是 Apache 旗下的开源消息中间件(Message-Oriented Middleware,MOM),也是 JMS(Java Message Service)1.1 规范的完整实现。本文是 ActiveMQ 系列文章的开篇,先讲清楚消息中间件是什么、解决什么问题,再介绍 JMS 的核心概念,为后续深入学习 ActiveMQ 的具体特性打好基础。 消息中间件解决什么问题?消息中间件是分布式系统中非常常见的组件。它的核心定位是作为应用程序之间的中介——各个应用不直接互相通信,而是通过消息中间件来传递消息。 两个最核心的价值:解耦和削峰。 解耦想象一个用户登录的场景:登录成功后,可能会有多个下游系统需要响应——给用户发欢迎消息、更新推荐算法、同步用户数据到数据仓库、触发风控检查……这些操作跟登录本身没有直接关系,如果把逻辑全部写在登录模块里,不仅代码会变成一锅粥,登录的响应时间也会变得不可接受。 引入消息中间件后,登录模块只需要在验证成功后发一条”用户已登录”的消息,其他系统各自监听这个消息,独立执行自己的业务逻辑。登录模块不再需要知道下游有哪些系统,新增一个...

hexo教程:博客系统搭建及部署到github
原文地址: https://lichuanyang.top/posts/19890/ Hexo是一款开源的博客系统。对于一个后端程序员来说,不想折腾前端的东西,但是csdn,博客园之类的用起来还是不太方便,自己搭博客又麻烦,做出来还丑。偶然间看到了hexo,这个对后端程序员来说可以说是非常友好了。所以也写篇文章记录一下hexo安装,一些关键配置,以及部署到github的过程。 安装及初始化参考官方文档 就可以了。hexo是基于node.js的,用过node的自然没有任何问题,没用过也没关系,照着说明文档做就可以了。 hexo支持直接向github的page发布,只需要配置好自己的github信息就可以。 主题hexo有很多定制主题, 按个人喜好使用吧, 我用的是next , 这款主题功能非常多,统计、搜索之类的都是一条配置都搞定了。不过这款的一些基础配置和其他主题似乎是有些区别的,所以用了以后如果以后想换别的可能会有点困难。 内容迁移hexo提供了多个从其他博客迁移数据的插件,rss,blogger等等都可以。 以博客园为例,博客园的博客可以导出一个rss文件,然后我们用hexo...
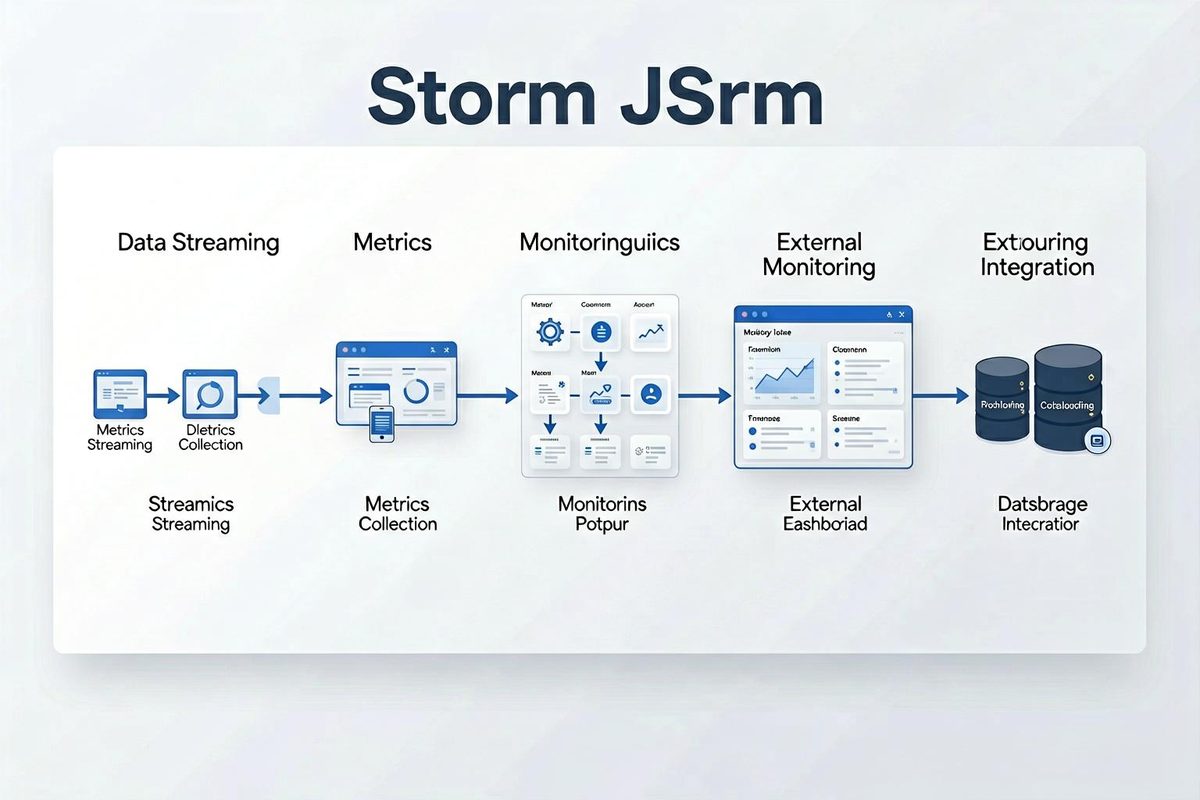
jstorm的监控metrics数据输出到第三方存储介质
JStorm Metrics 体系Jstorm的UI中提供了大量非常详细的监控参数,对于我们排查问题帮助非常大,关于UI,可以参考我之前的另一篇文章: https://lichuanyang.top/posts/31996/ 。 不过,UI这种方式用起来有时可能会不太方便,比如需要查历史数据的时候。所以我们希望将监控数据输出到别的存储介质中,方便后续查询、分析。 由于jstorm的监控相比于apache-storm进行了完全的重写,所以网上查到的storm的监控输出方式并不适用于jstorm. 而jstorm除了官方文档以外实在缺少资料,官方文档又太简略,给的只是一些线索性的东西,具体还要结合这些线索去翻阅源码。所以我整理了一个jstorm监控数据输出的例子。 自定义 Metrics 上报首先需要实现MetricUploader这个接口,不过其实我们并不会实际使用这个接口里的哪个方法,主要是要去用它的TopologyMetricsRunnable这个参数,然后用这个参数去取监控信息。所以理论上只要拿到TopologyMetricsRunnable就行,并不一定非要实现Metric...