redis的对象
在上一篇文章中,介绍了redis的底层定义的一些数据结构。接下来,在本文中,我们就结合redis提供的对象,看看这些数据结构是如何使用的。 Redis中主要包括这些对象:字符串、列表、哈希、集合、有序集合、HyperLogLog、GEO等,本文会主要介绍这些对象是如何实现的,对于其命令,可以参考redis官网中对每个命令的说明,这里就不一个一个列了。 在介绍具体的对象之前,先看一下redis中对于对象本身的定义。 123456789typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 ...
redis里的数据结构
Redis作为当前使用非常广泛的内存数据库,在代码层面做了很多极致的优化,已获取更好的性能。其中重要的一部分,就是对于底层数据结构的使用。Redis会根据数据量、数据大小等来优化对于不同结构的使用,从而获得更佳的运行效率和内存占用。Redis的核心数据结构包括简单动态字符串、列表、字典、跳跃表、整数集合、压缩列表。 接下来,我们就依次讲讲这些数据结构。 简单动态字符串(SDS)Redis是用C语言实现的。先复习一下C,C里的字符串中不记录字符串长度,以空字符标记结尾。这样会显而易见的带来三个问题:1.获取字符串长度需要O(n)的复杂度;2.操作不慎会导致缓冲区溢出,例如内存中紧邻的两个字符串,如果对前一个调用strcat拼接其他字符串,就会造成溢出;3. 一些特殊内容,如图像、音频等转成二进制时,难免其中夹杂空字符等特殊字符,这样就无法被C字符串存储了,即C字符串不具备二进制安全性。 而这几点,对于Redis的应用场景来说,影响其实都是非常大的。因此,在redis中定义了一个新的结构,用来保存字符串,即SDS。 SDS的核心思想就是额外使用一个字段记录字符串的长度,这样,上面...
设计模式备忘录
众所周知,对于程序员来说,设计模式是一门极其重要的学科。不过,由于设计模式的涉及面太广,也有很多非常抽象的概念,还是很难掌握的。要学习设计模式,最好还是能结合实际。每次做需求,尤其是一些复杂的需求,或者嗅到了烂代码味道的时候,就可以翻一遍设计模式,看看有什么可以应用的模式。所以,我总结了这篇文章,以尽量短的语言描述主要的设计模式,可能是定义中的关键部分,也可能是典型的应用场景,或者只是个英文单词,目的在于帮助回忆起每个设计模式的作用和应用场景。 基本设计原则要说设计模式,一定要先提一遍六大基本设计原则。说白了,设计模式就是在这些原则的基础上被提炼出来得一系列最佳实践。 单一职责原则开放封闭原则通过扩展解决问题,而不是修改已有的实现。(写代码时可以假定变化不会发生,当出现变化时,需要抽象以隔离将来的同类变化) 修改没有破坏原有的单元测试,即可认为不违反开闭原则 里氏替换原则子类应当能代替父类 依赖倒置原则高层模块不能依赖低层模块;应当依赖抽象而非实现 接口隔离原则接口尽量小 迪米特法则类间解耦 #设计模式 工厂方法模式定义一个用于创建对象的接口 抽象工厂模式创建一组相关或者相...

聊聊程序员的职业生涯,我对程序员这个职业的理解
工作这些年来,一直在思考着程序员这个职业究竟是在做什么,随着经验增多,其实也一直在刷新着认知。现在写这篇文章,一方面是为了分享,另一方面也是想留下一份记录,过两年再回头来看看自己的认知又有了什么更新。 程序员职业的本质我想从两个方面来说。一是从做的事儿上,在我看来,程序员的工作就是发现问题、分析问题、解决问题三类。事实上,世界上绝大多数工作都可以囊括进这三类事中。二是从能力上来看,我把能力分为两种:对现实世界的认知能力,和将现实世界映射成程序语言的能力。 对于三种类型的事,按发现问题,分析问题,解决问题的顺序,是从宏观到细节的区别,平时做的事,肯定是以解决问题为主,各种琐碎的事,也都是在解决问题。发现问题和分析问题对人的思维深度会有更高的要求,不过对于工作来说,我倒并不觉得这三类事有什么高下之分。如果对确定的问题,总能给出恰当的解决方案,这也是职场上非常硬核的核心竞争力。而对于两类能力,一般还是更关注第二种。但是我觉得对现实世界的认知能力,对于程序员的职业发展是非常重要的。就像抠业务,抠CRUD这事,有门槛吗?我觉得是有的,至少把业务做的很好门槛非常高。有些人总是以非常奇特的...
通过mysql批量操作不生效问题聊聊java里mysql的batch
众所周知,对于mysql,使用批量操作,可以大幅度提升大数据量下操作的性能。不过,在java中使用mysql时,有些细节务必注意,否则就会导致batch操作不生效,也就享受不到批量操作的性能了。 问题现象前阵子,发现一条sql的性能明细不正常,几千条数据批量insert,耗时居然到了秒级。排除了服务器性能、网络的问题后,开始怀疑是代码的问题,导致batch操作没有真正生效,感觉只有一条一条去跟数据库交互的话才会出现这种性能。 MySQL JDBC Batch 原理调了一下代码,翻到了mysql-connector里,关键的代码是这么一块: 12345678910111213if (!this.batchHasPlainStatements && this.connection.getRewriteBatchedStatements()) { if (canRewriteAsMultiValueInsertAtSqlLevel()) { return exec...
【实践经验】单元测试怎么写
之前一段时间,在尝试完善项目的单元测试,做起来才发现,其实自己对于单元测试该怎么写一直没有特别清晰的认识,因此查了一些资料, 查的过程中发现,其实每个人的看法都不尽相同。每阅读一篇文章,都是对自己认知的一次更新。本文就是结合前人的看法,和自己的实践经验,总结出一些我自己当前认知状态下认为正确的东西,分享给大家。估计也不会是最正确的,也欢迎大家留言讨论。 先说一下我们写单元测试的目的,这个是下边所有讨论的基础。单元测试的意义应当在于保障修改代码的时候,保障存量代码的正确性。也就是说,修改代码后,执行一遍已有的测试用例,能执行的话就代表之前的逻辑依然是可用的。 下面就具体列一下个人认为写单元测试应当遵守的准侧。 避免对环境的依赖单元测试不应当依赖于环境,包括对网络、db、io、数据、外部接口等的依赖。这一点应该争议不大,因为单元测试会有很多的执行场景,比如开发人员手动触发、提交代码时自动触发、打包时自动触发等,如果单元测试不能解除对环境的依赖,它的执行场景就会大大受限。 实现这一点,需要借助很多工具,例如内存数据库、redis的内嵌server, mock等待,势必会给写单元测试这...
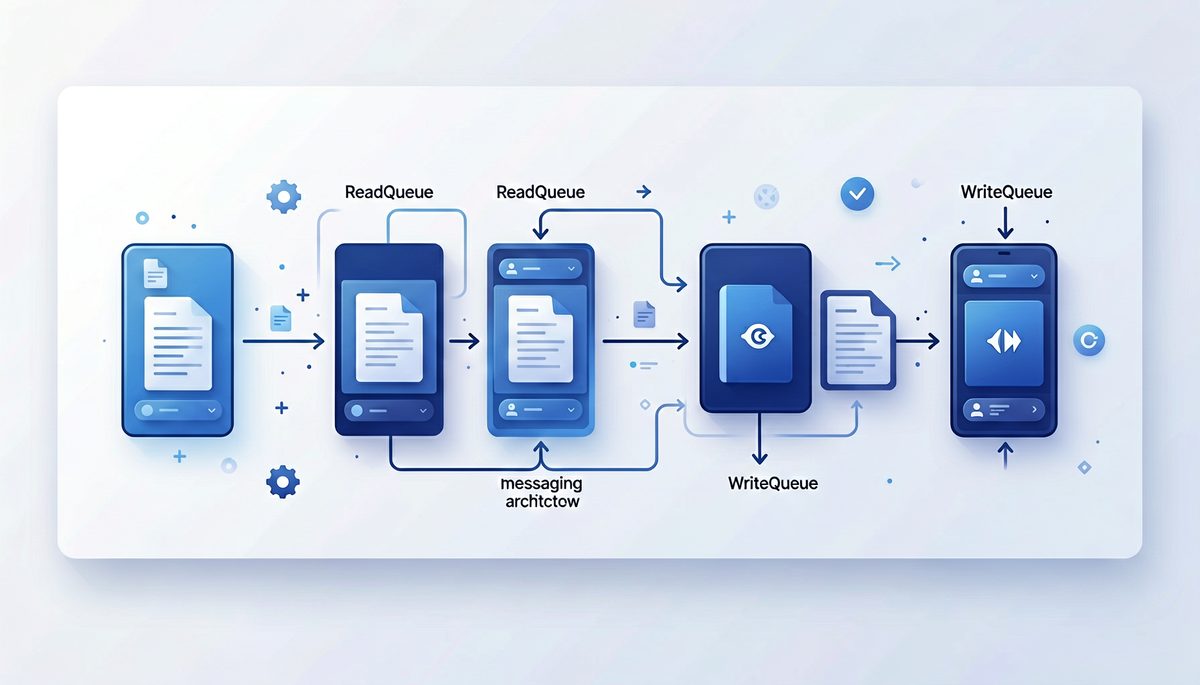
关于rocketmq的readQueue和writeQueue
RocketMQ 的 MessageQueue 有一个独特设计:将队列拆分为 readQueueNums(读队列数)和 writeQueueNums(写队列数)。这两个值在绝大多数情况下必须相等,一旦不等就会产生严重问题——那为什么要拆开?答案在于平滑扩缩容。 MessageQueue 是什么?在 RocketMQ 中,Topic 是消息的逻辑分类,而 MessageQueue 是 Topic 的物理分片,类似于 Kafka 的 Partition。关键约束:Consumer 的数量不能超过 Queue 的数量——因为每个 Queue 同一时间只能被一个 Consumer 消费。 正常状态下:readQueue = writeQueue正常情况下,readQueueNums == writeQueueNums,生产者向所有 Queue 写入消息,消费者从所有 Queue 读取消息,一切正常。 但如果两者不一致: 状态 后果 writeQueue > readQueue 部分 Queue 有写无读 → 消息永远不会被消费,积压 readQueue...
数据分析的利器-clickhouse介绍
Clickhouse是Yandex开源的一个用于实时数据分析的数据库,一开始就用在yandex内部的多个数据分析业务上。要介绍clickhouse,还是需要先介绍一下yandex。Clickhouse为什么会出现,其实和yandex的业务关系非常大。Yandex是俄罗斯最大的搜索引擎,会有很多数据分析的业务,其中数据量最大的业务,就是Yandex.Metrica,这是一个和百度统计类似的网站数据分析服务,数据量也仅次于google analysis。自从Clickhouse开源后,在国内外的很多公司的线上业务都已经开始使用。 因此,写这篇clickhouse教程,对clickhouse做一个基础的介绍。 概述Clickhouse是极其适合OLAP(联机分析处理)问题的一个数据库。这类问题有如下一些特点: 请求以读为主,数据添加、更新一般以批量的形式进行; 表可以很宽,但是实际查询时只会用到有限的几列; 列值较小,一般是数字或者短字符串; 查询结果集的大小显著小于源数据; 事务处理需求较弱 根据clickhouse提供的性能测试结果,clickhouse的性能要大大领先于所...

通过位运算转换大小写
位运算是计算机科学中最基础也最高效的操作之一。今天介绍一个经典的位运算应用:用一行代码完成英文字母的大小写转换。 为什么需要位运算做大小写转换?你可能第一反应是:Java 不是有 Character.toUpperCase() 和 Character.toLowerCase() 吗?为什么要自己写? 确实,99% 的场景下你应该用标准库。但了解这个技巧有几个价值: 面试中的常见考点:很多算法面试会考察这种位运算思维 理解计算机底层:知道 ASCII 码的设计精妙之处 嵌入式/底层开发:在没有标准库的环境下,这就是实际操作 代码简洁:ch ^= 32 比 Character.isUpperCase(ch) ? Character.toLowerCase(ch) : ch 优雅得多 ASCII 码的巧妙设计要理解这个技巧,先看英文字母在 ASCII 表中的编码: 字母 十进制 十六进制 二进制 A 65 0x41 0100 0001 a 97 0x61 0110 0001 B 66 0x42 0100 0010 b 98 0x62 0110 ...
activemq多线程消费的不同处理方式
问题场景之前在另一篇文章里介绍过使用activemq时,client端的基本语法。 值得注意的是消费者, 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849 public void consume() throws JMSException { ActiveMQConnectionFactory cf = new ActiveMQConnectionFactory(); cf.setBrokerURL("tcp://localhost:61616"); Connection connection = cf.createConnection(); connection.start(); Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE); ...