数据分析的利器-clickhouse介绍
Clickhouse是Yandex开源的一个用于实时数据分析的数据库,一开始就用在yandex内部的多个数据分析业务上。要介绍clickhouse,还是需要先介绍一下yandex。Clickhouse为什么会出现,其实和yandex的业务关系非常大。Yandex是俄罗斯最大的搜索引擎,会有很多数据分析的业务,其中数据量最大的业务,就是Yandex.Metrica,这是一个和百度统计类似的网站数据分析服务,数据量也仅次于google analysis。自从Clickhouse开源后,在国内外的很多公司的线上业务都已经开始使用。 因此,写这篇clickhouse教程,对clickhouse做一个基础的介绍。
概述
Clickhouse是极其适合OLAP(联机分析处理)问题的一个数据库。这类问题有如下一些特点:
- 请求以读为主,数据添加、更新一般以批量的形式进行;
- 表可以很宽,但是实际查询时只会用到有限的几列;
- 列值较小,一般是数字或者短字符串;
- 查询结果集的大小显著小于源数据;
- 事务处理需求较弱
根据clickhouse提供的性能测试结果,clickhouse的性能要大大领先于所有同类产品。
针对这类问题,用到的最核心的思路就是列式存储。目前常用的数据库,像MySQL等,都是行式存储。而列式存储,简单的说就是把同一列的数据存储在一起,像下图这样。
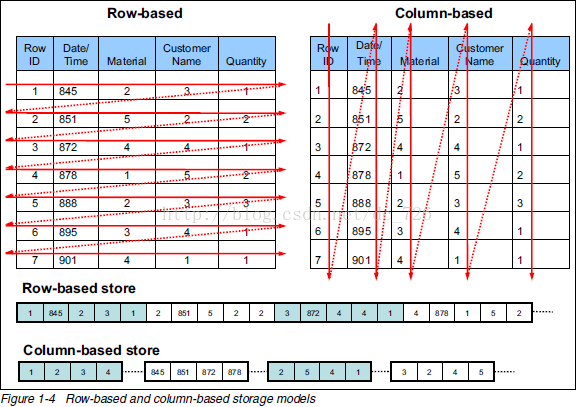
相对行存储, 列存储查询时只会读取涉及到的列,减少io开销;任何一列都可以作为索引;但是数据写入会相对麻烦一些。对比前面我们介绍的OLAP问题的特点,可以看到,列式存储是及其适合这种在线数据分析的。
ClickHouse的存储引擎
ClickHouse中提供了很多种存储引擎,不过90%以上的情况下用MergeTree这个引擎就可以了。下面详细介绍一下这个引擎。
简单来说,mergeTree有这么几个特点:
- 分块(part)存储(一般按日期);
- part内按主键排序,并分成多个block;
- 插入时生成新的part;
- 异步merge
首先来看一下mergeTree的文件结构。(本节的图片都来自clickhouse中文社区(http://clickhouse.com.cn/)内来自新浪高鹏老师的分享)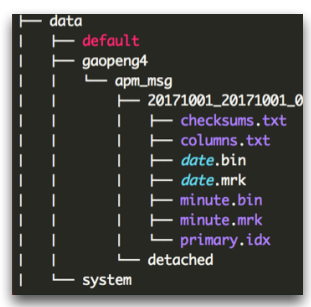
其中20171001….这个目录就是代表一个part,下面这些文件,columns.txt记录列信息;每一列有一个bin文件和mrk文件, 其中bin文件是实际数据,primary.idx存储主键信息,结构与mrk一样,类似于稀疏索引。
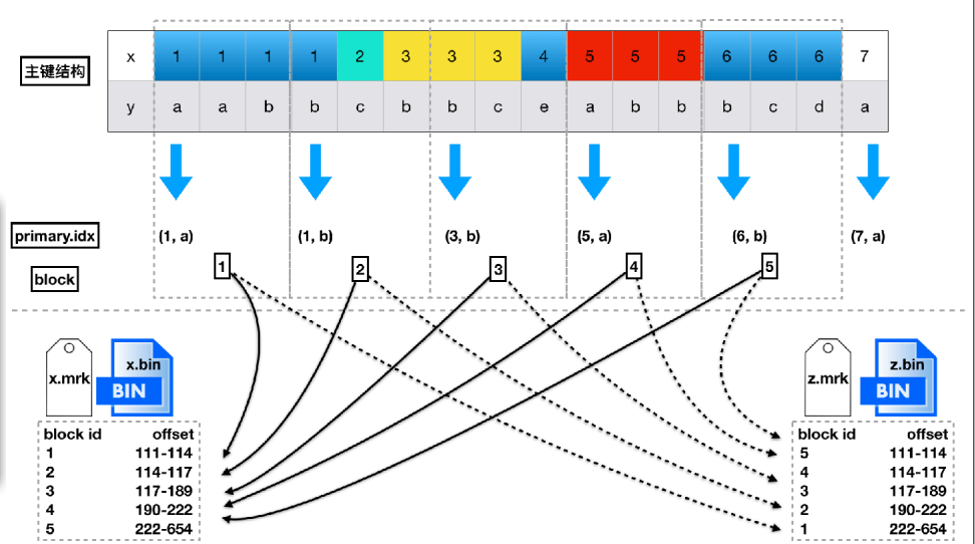
这里展示了mrk文件和primary文件的具体结构,可以看到,数据是按照主键排序的,并且会每隔一定大小分隔出很多个block。每个block中也会抽出一个数据作为索引,放到primary.idx和各列的mrk文件中。
而利用mergetree进行查询时,最关键的步骤就是定位block,这里会根据查询的列是否在主键内有不同的方式。根据主键查询时性能会较好,但是非主键查询时,由于按列存储的关系,虽然会做一次全扫描,性能也没有那么差。所以索引在clickhouse里并不像mysql那么关键。实际使用时一般需要添加按日期的查询条件,保障非主键查询时的性能。
找到对应的block之后,就是在block内查找数据,获取需要的行,再拼装需要的其他列数据。
其他特性
数据压缩
一些面向列的DBMS(例如InfiniDB CE和MonetDB)没有使用数据压缩。但是,对于clickhouse的性能提升,数据压缩起到了很大作用。对于列式存储来说。相同的字段存储在一起,类型一致,数据类似,更方便进行压缩。clickhouse支持LZ4和ZSTD等压缩算法。
基于磁盘存储
clickhouse支持普通磁盘;因此在成本上有较大优势。
提供了针对raid, ssd,大内存等的配置,如果有的话,也能加以利用。
数据按主键顺序存储,因此可以实现延时极低的查询。
向量化引擎
现代CPU中有一种叫SIMD的机制,即Single Instruction, Multiple Data,一条指令操作多个数据。对于列式存储的数据,可以很方便的利用这一机制,更好的发挥cpu的性能。
多核,多服务器并行处理
在clickHouse中,数据会存储到不同的分片上。查询会在多个分片上并行执行。
而在每台服务器上,也会多核并行处理,充分利用单机性能。
支持数据实时写入
mergetree引擎下,新插入数据后,会先形成新的part, 这个时候数据就已经可以被查到,因此从数据写入到可以被查询的延时是很小的。后续不同part会继续异步进行merge, 以提高存储效率
数据复制
clickHouse是基于zookeeper的主主复制。写入任何可用的副本后,数据将分发到所有剩余的副本。复制时是按块进行,复制失败的话可以直接重试。系统在不同的副本上保持相同的数据。
此外,相对其他列存储数据库,clickhouse对sql语法的支持非常好,包括group by, order by, in, join等常用sql语句都支持。